概述
boyue vGPU軟件是一個為雲或者資料中心內的AI應用,CUDA應用提供GPU資源池化,提供GPU虛擬化能力的系統軟體。 通過高效的通訊機制,使得AI應用,CUDA應用可以運行在雲或者資料中心內任何一個物理機,Container或者VM內而無需掛載物理GPU。 同時為這些應用程序提供在GPU資源池中的硬體算力。 通過這種boyue GPU池化的能力,可以提供多個優點:
- 兼容已有的AI應用和CUDA應用,使其仍然具有使用GPU加速的效能
- 为AI應用和CUDA應用在云和数据中心的部署提供了很大的灵活度。无需受GPU服务器位置、资源数量的约束。
- boyue GPU资源随AI應用和CUDA應用启动时分配,随應用程序退出时自动释放。减少GPU空闲时间,提高共享GPU的周转率。
- 通過對GPU資源池的管理和優化,提高整個雲和資料中心GPU的利用率和吞吐率。
- 通過統一管理GPU,減輕GPU的管理複雜度和成本。
支持清單
處理器
- x86_64
作業系統
- 64位CentOS 6 /7
- 64位 Ubuntu 16 / 18 / 20
NVIDIA GPU
- NVIDIA Tesla系列:H系列、L系列、A系列、T系列、V系列、P系列、M系列
- NVIDIA GeForce系列:RTX 30系列、RTX 20系列、GTX 10系列、GTX 98/97/96/95/75系列
- NVIDIA Quadro 系列:RTX系列、GV/GP系列、P系列、M系列
寒武紀 MLU
- MLU-370-X4 / X8
- MLU-270-X5K
中科海光 DCU
- Z100L、Z100
NVIDIA CUDA
- CUDA 12.0,12.1
- CUDA 11.0, 11.1, 11.2, 11.3, 11.4,11.5,11.6,11.7,11.8
- CUDA 10.0, 10.1, 10.2
- CUDA 9.0, 9.1, 9.2
寒武紀 Neuware
- Neuware-3.4.2
- Neuware-3.0.2
- Neuware-2.8.5
- Neuware-2.7.3
- Neuware-2.6.4
- Neuware-2.5.2
中科海光 DTK
- DTK-22.04
深度學習框架
- TensorFlow for CUDA : 1.8 - 2.12
- TensorRT : 5.x / 6.x / 7.0 / 7.1 / 7.2 /8.x
- Pytorch for CUDA : 1.0 - 2.0
- PaddlePaddle: 1.5 / 1.6 / 2.0 / 2.1 / 2.2/ 2.3.2
- ONNX : 1.0 / 1.1 / 1.2 / 1.3 / 1.4 / 1.5 / 1.6 / 1.7 / 1.8 / 1.9 / 1.10 / 1.11/1.12
- MXNet :1.4.1 / 1.6 / 1.7 / 1.8 / 1.9
- XGBoost :0.72、0.8、0.9
- NVCaffe :1.0
- Cambricon Tensorflow for Neuware:1.15 / 2.4
- Cambricon Pytorch for Neuware:1.6 / 1.9
- Cambricon Tensorflow Horovod:0.12.1
- Cambricon Magicmind:0.6
- DTK Tensorflow :1.15/2.7
- DTK PyTorch:1.10
- DTK PaddlePaddle:2.3.0
網絡
- TCP/IP以太網络
- RDMA網络(InfiniBand和RoCE)
容器環境
- Docker 12.03 及以後版本
虛擬化環境
- QEMU-KVM (QEMU 2.8以上)
容器框架
- Kubernetes 1.10 及以後版本
更多相容環境未逐一列出,聯繫我們詳細瞭解
已知問題
下麵列出當前版本不支持的CUDA庫、工具以及使用模式
- 不支持CUDA應用程序使用 Unified Memory
- 不支持 nvidia-smi 工具
- 有限支持CUDA IPC,對部分程式可能不支持。
必要組件介紹
boyue Controller
該組件為一個長運行的服務程式,其負責整個GPU資源池的資源管理。 其響應boyue Client的vGPU請求,並從GPU資源池中為boyue Client端的CUDA應用程序分配並返回boyue vGPU資源。
該組件可以部署在資料中心任何網絡可到達的系統當中。 每個資源池部署一個該組件。 資源池的大小取決於IT管理的需求,可以是整個資料中心的所有GPU作為一個資源池,也可以每個GPU服務器作為一個獨立的資源池。
boyue Server
該組件為一個長運行的系統服務,其負責GPU資源化的後端服務程式。 boyue Server部署在每一個CPU以及GPU節點上,接管本機內的所有物理GPU。 通過和boyue Controller的互動把本機的GPU加入到由boyue Controller管理維護的GPU資源池當中。
當boyue Client端應用程序運行時,通過boyue Controller的資源調度,建立和boyue Server的連接。 boyue Server為其應用程序的所有CUDA調用提供一個隔離的運行環境以及真實GPU硬體算力。
boyue Client
該組件為一個運行環境,其類比了NVidia CUDA的運行庫環境,為CUDA程式提供了API介面相容的全新實現。 通過和boyue其他功能組件的配合,為CUDA應用程序虛擬化了一定數量的虛擬GPU(boyue vGPU)。
使用CUDA動態連結程式庫的CUDA應用程序可以通過作業系統環境設定,使得一個CUDA應用程序在運行時由作業系統負責連結到boyue Client提供的動態連結程式庫上。 由於boyue Client類比了NVidia CUDA運行環境,囙此CUDA應用程序可以透明無修改地直接運行在boyue vGPU之上。
典型部署架構
以下介紹兩種常見的boyue GPU資源池化部署方案。 一種是All-in-One的本地GPU虛擬化方案,一種是部署到分佈式多臺物理機的GPU資源池化方案。
boyue GPU 資源池化方案
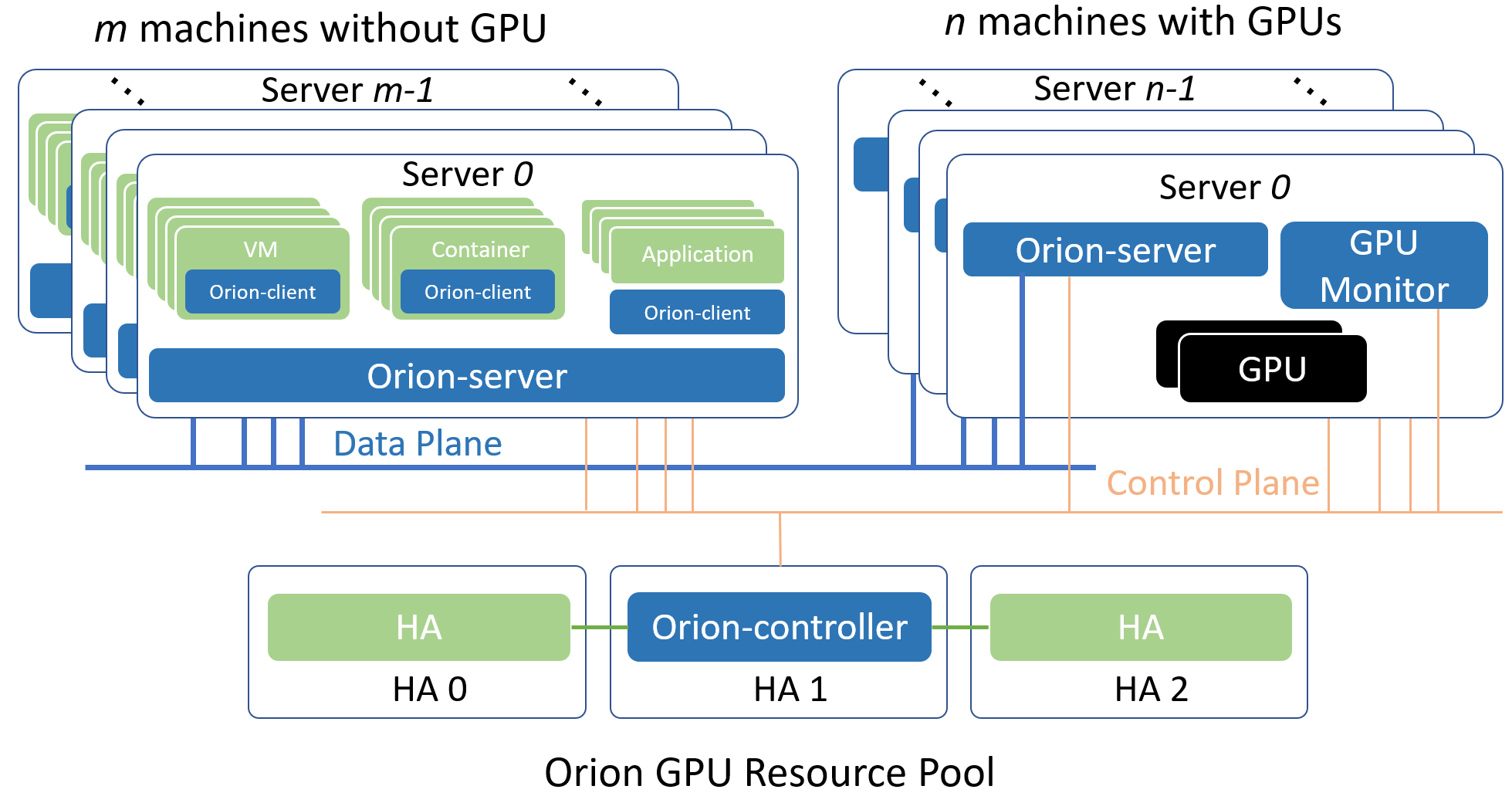
分佈式GPU資源池化方案指的是把一臺或者多臺服務器內的GPU作為資源池,通過boyue向局域網內任一個物理機、Container或者VM內的CUDA應用程序提供虛擬化GPU的部署管道。
選擇局域網內至少一個Linux服務器部署boyue Controller。 該Controller必須可以被屬於同一個資源池的其他boyue組件通過網絡訪問。
每一個服務器上部署boyue Server服務,boyue Server自動適配該服務器是否安裝有GPU,從而開啟不同的功能。
在每一個需要運行CUDA應用程序的物理機、Container和VM裏部署boyue Client運行庫。
各個boyue組件通過boyue Controller的控制功能完成服務發現,資源調度等功能。
從邏輯上,以上各個boyue組件使用了control plane和data plane兩套網絡。 其中control plane用於和boyue Controller組件的通訊。 該部分通訊流量不大,對網路延遲和頻寬需求不高。 data plane用於boyue Client和boyue Server之間執行CUDA任務之間的通訊。 該部分對於網絡的延遲和頻寬有一定需求。 建議使用支持RDMA的網絡。 在實際環境中,control plane和data plane可以是同一個物理網絡。
安裝部署
以下安裝部署的步驟,說明,均以boyue套裝軟體存放路徑在/root/boyue為例進行說明
GPU Monitor
該組件為可選組件,用於監控物理GPU的利用率。 如果生產環境中已有其他替代的功能,該組件可以不用部署。
環境依賴
- Docker容器環境
- 與Docker版本匹配的Nvidia Docker runtime
- Nvidia GPU驅動
執行如下命令導入容器鏡像,並運行服務
cd /root/boyue/gpu-monitor
gunzip dcgm-exporter.tar.gz | docker load
gunzip node-exporter.tar.gz | docker load
./run-nvidia-exportor.sh
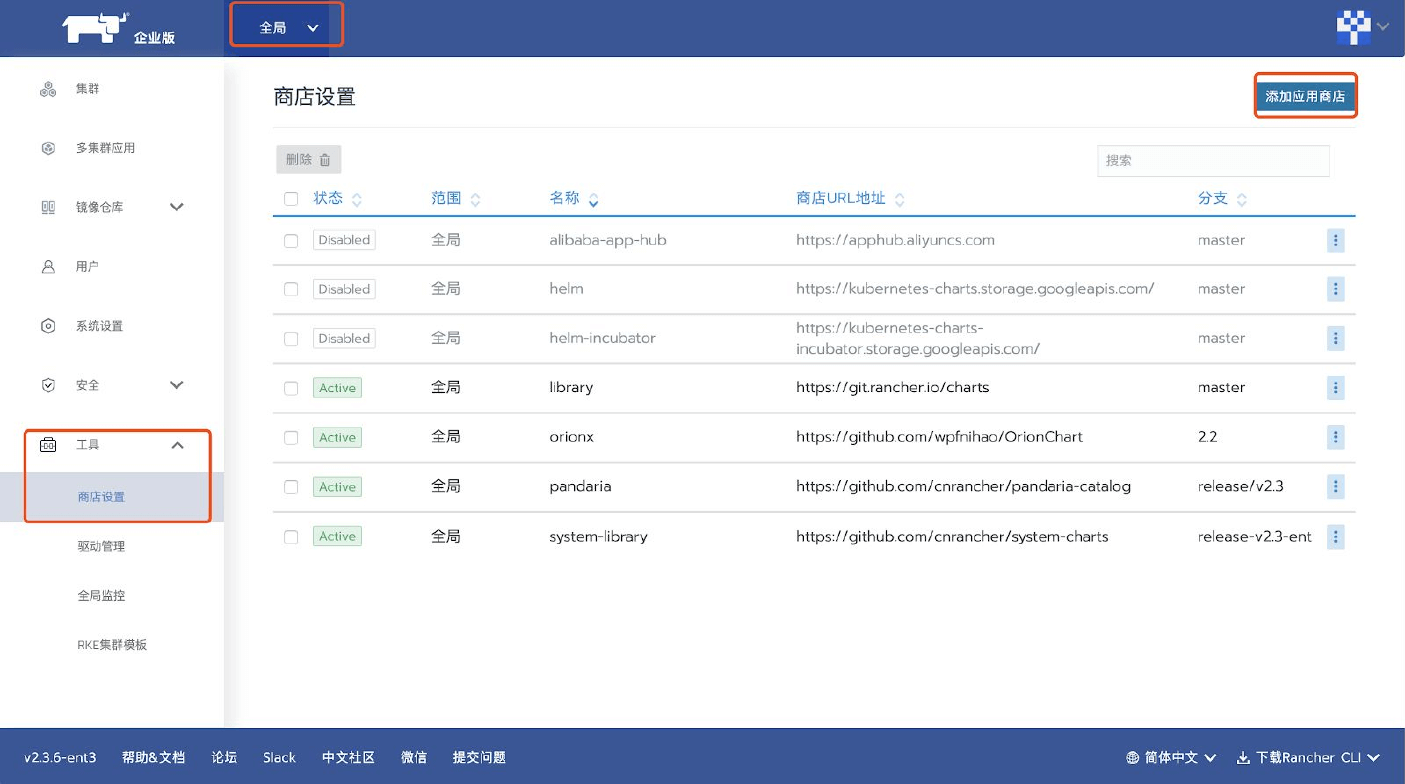
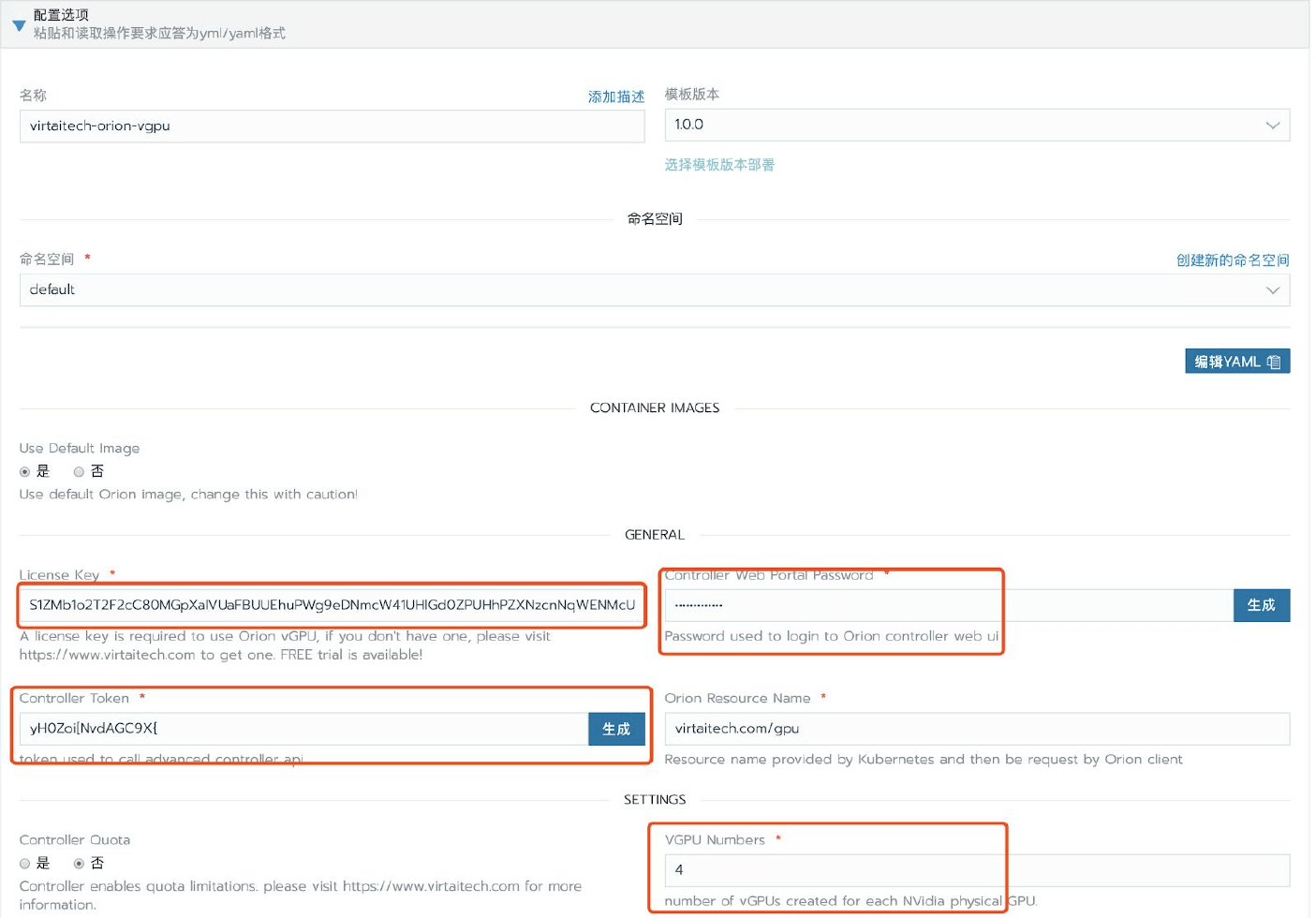
boyue Controller
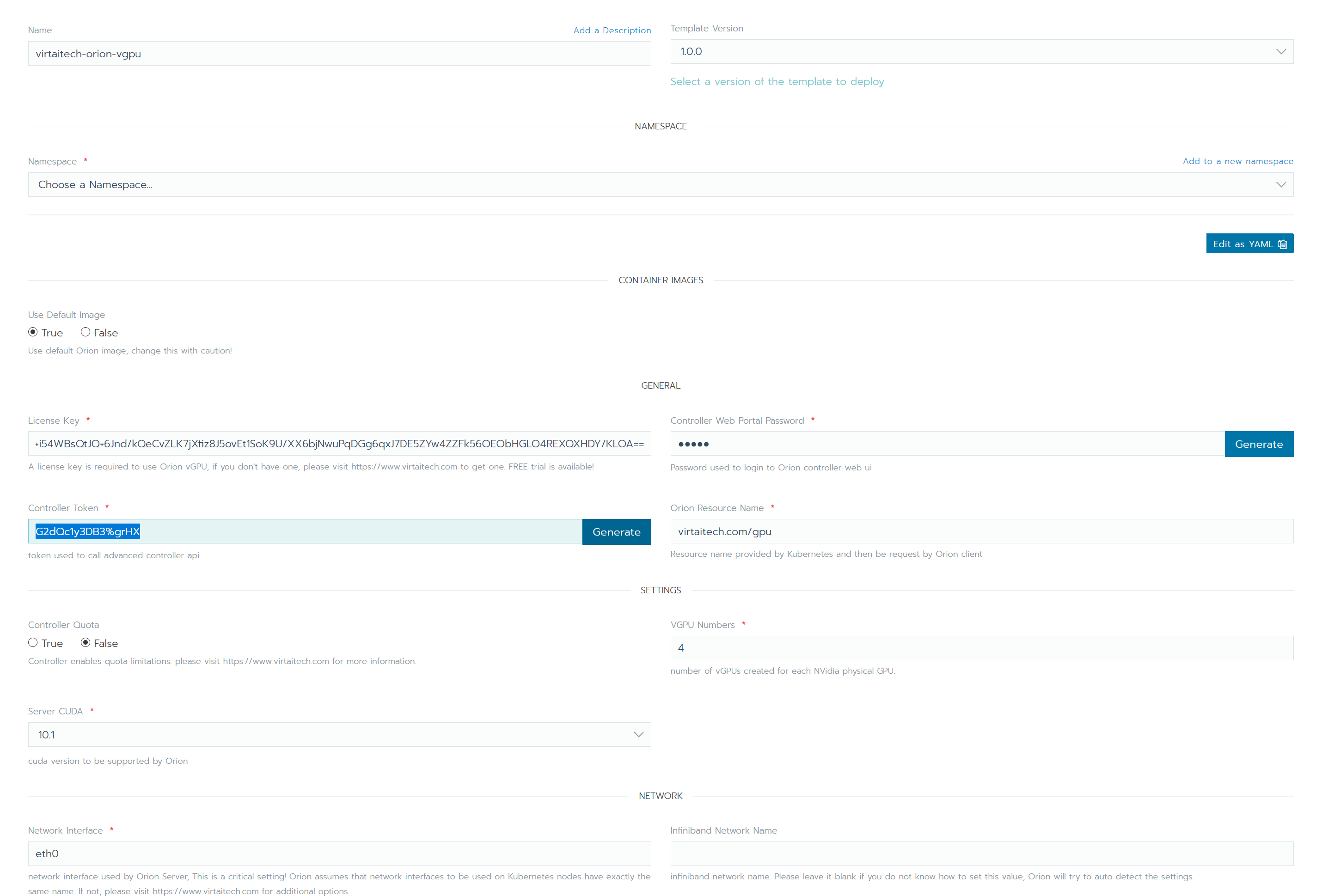
boyue Controller包括物理GPU管理,vGPU資源分配,GUI監控,管理功能。 在典型使用場景下,在一個分佈式環境,僅需要部署一個實例。 以下通過容器化部署boyue Controller。
環境依賴
- Docker容器環境
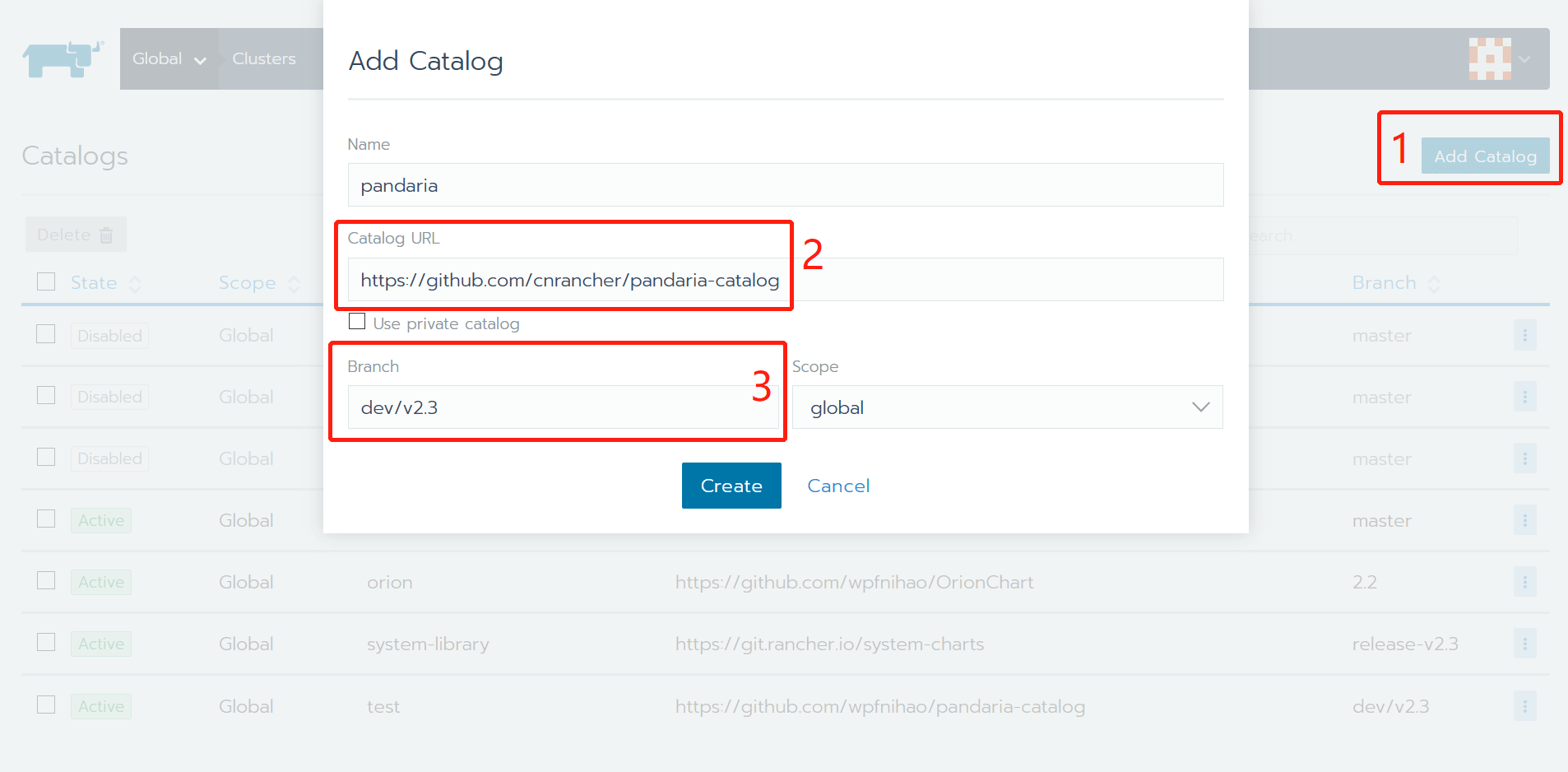
啟動文件下載
用戶在部署boyue Controller之前,需確保已經下載啟動檔案。
如何下載啟動檔案:
進入數字中國官网
進入產品頁面
經管理員稽核後,成功申請試用,或者已經付費購買的用戶,可以進入您的個人中心頁面,點擊“下載啟動檔案”按鈕獲取您的啟動檔案。 對於聯網環境和非聯網環境的用戶,需要下載啟動檔案的管道有所不同,詳情請參攷“下載啟動檔案”頁面描述。

进入/root/boyue/controller目录
cd /root/boyue/controller用您下載到的啟動檔案license.txt替換/root/boyue/controller目錄裏的已有的license.txt即可。
啟動 boyue Controller 服務
執行如下命令導入容器鏡像,並運行服務
cd /root/boyue/controller
gunzip boyue-controller-ent-2.2.tar.gz | docker load
gunzip prometheus.tar.gz | docker load
編輯設定檔 /root/boyue/controller/prometheus.yml
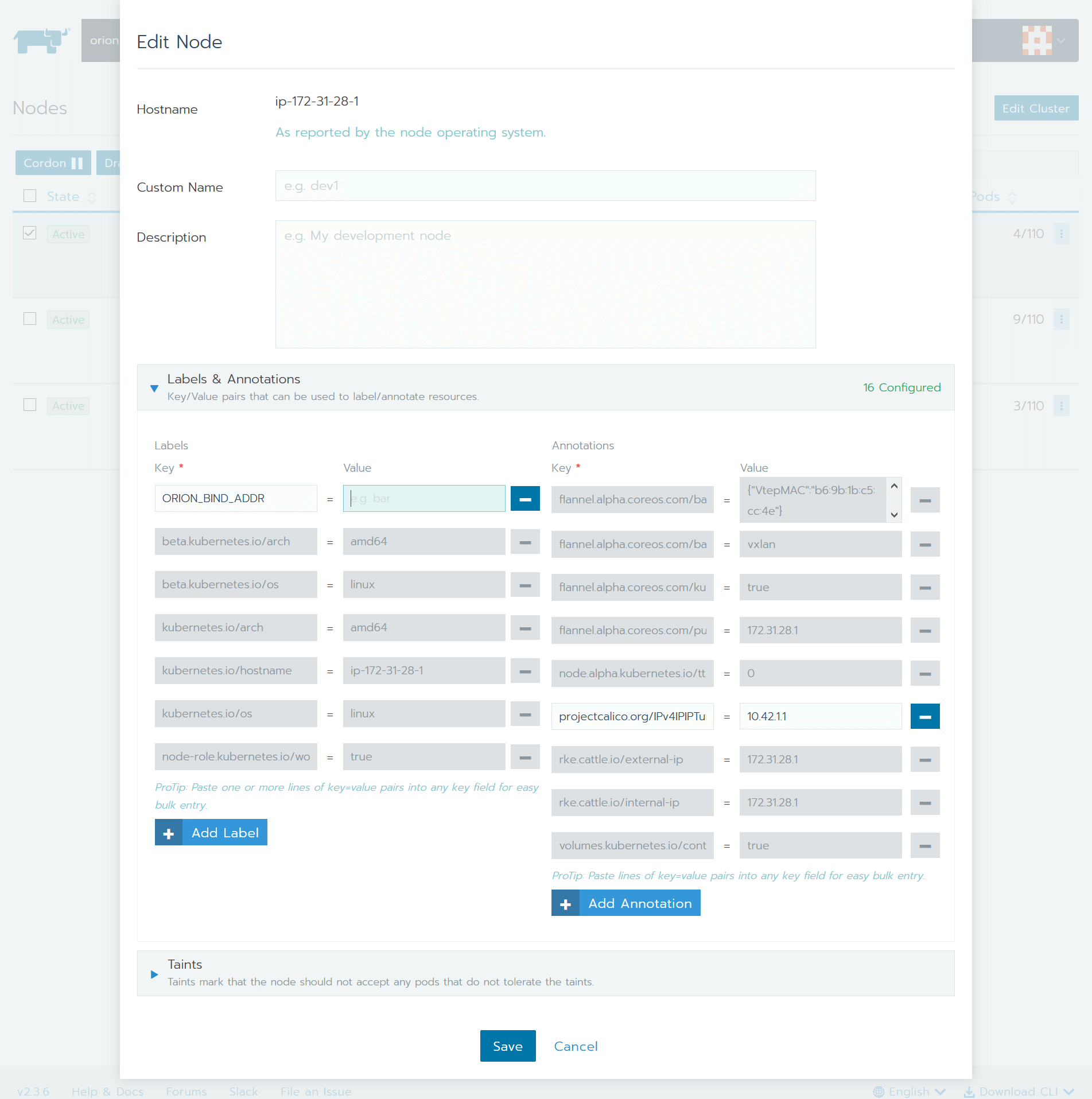
修改staticconfigs中的targets 清單,該清單是安裝了GPU Monitor服務的GPU服務器的清單。 當GPU Monitor有多個IP網段地址的時候,該地址應該與第3章節部署boyue Server時綁定的數據網段相同,例如檔案中的“boyueBINDADDR=CCCC”地址,或者是boyue Server的設定檔中的bindaddr相同。
執行如下命令運行boyue Controller服务:
cd /root/boyue/controller
./run-controller.sh
服務成功啟動後,根據荧幕輸出提示,在本宿主機的所有網段提供如下服務:
- 調度服務:部署boyue Server時需要配寘該地址
- Web GUI服務:通過瀏覽器訪問該服務進行監控和管理
boyue Controller的日誌檔
boyue Controller的日誌檔存放在boyue Controller容器內的/root/controller.log中
boyue Server
boyue Server為GPU資源池化提供底層的虛擬GPU服務。 在所有的CPU節點、GPU節點均需部署該服務。
boyue Server支持的虛擬化/容器平臺有:
- Docker :>= 1.13
- Libvirt + QEMU-KVM : QEMU > 2.0.0
CUDA業務運行KVM虛擬的場景,在把boyue Server部署至宿主機時,由於宿主機可能存在SELinux,apparmor的限制,安裝boyue Server之後的配寘,僅對安裝之後新創建的虛擬機器,或者是從Power OFF狀態重新啟動的虛擬機器生效。
環境依賴
對於無物理GPU的CPU節點
- g++ 4.8.5 或以上版本
- Linux基本庫依賴libcurl3, libibverbs1, numactl-libs(libnuma), libvirt-devel
- 如果使用Mellanox RDMA網絡,需要安裝RDMA驅動,以及Mellanox的OFED
GPU節點額外的環境需求
- 安裝有 Nvidia 物理 GPU 驅動
- NVIDIA CUDA SDK 9.0, 9.1, 9.2, 10.0, 10.1
- NVIDIA CUDNN 7.4.2 以上版本,推薦 7.6.x
- NVIDIA NCCL 和最高CUDA SDK版本匹配
在CPU、GPU 服務器宿主機執行如下命令安裝 boyue Server
cd /root/boyue/server
sudo ./install-server.sh
配寘 boyue Server
通過設定檔 /etc/boyue/server.conf 可以對 boyue Server 進行必要的配寘,其中支持的配置選項有:
[log]
log_with_time = true ; 记录日志的时候是否添加时间戳
log_to_screen = true ; 日志是否输出到屏幕的标准输出
log_to_file = true ; 是否记录日志至磁盘文件中
log_level = INFO ; 日志级别,支持 INFO, DEBUG
file_log_level = INFO ; 日志输出到文件中的日志级别
[controller]
controller_addr = 127.0.0.1:9123 ; boyue Controller的调度器IP地址和端口
[server]
vgpu_count = 4 ; 默认一个物理GPU被拆分成多少个vGPU
bind_addr = 127.0.0.1 ; data plane的IP地址
;bind_net = ; data plane的网络名字,例如eth0, eth1。bind_addr 和 bind_net 仅能配置1个
listen_port = 9960 ; boyue Server的服务端口
enable_kvm = true ; 是否支持boyue Client运行在KVM的VM中
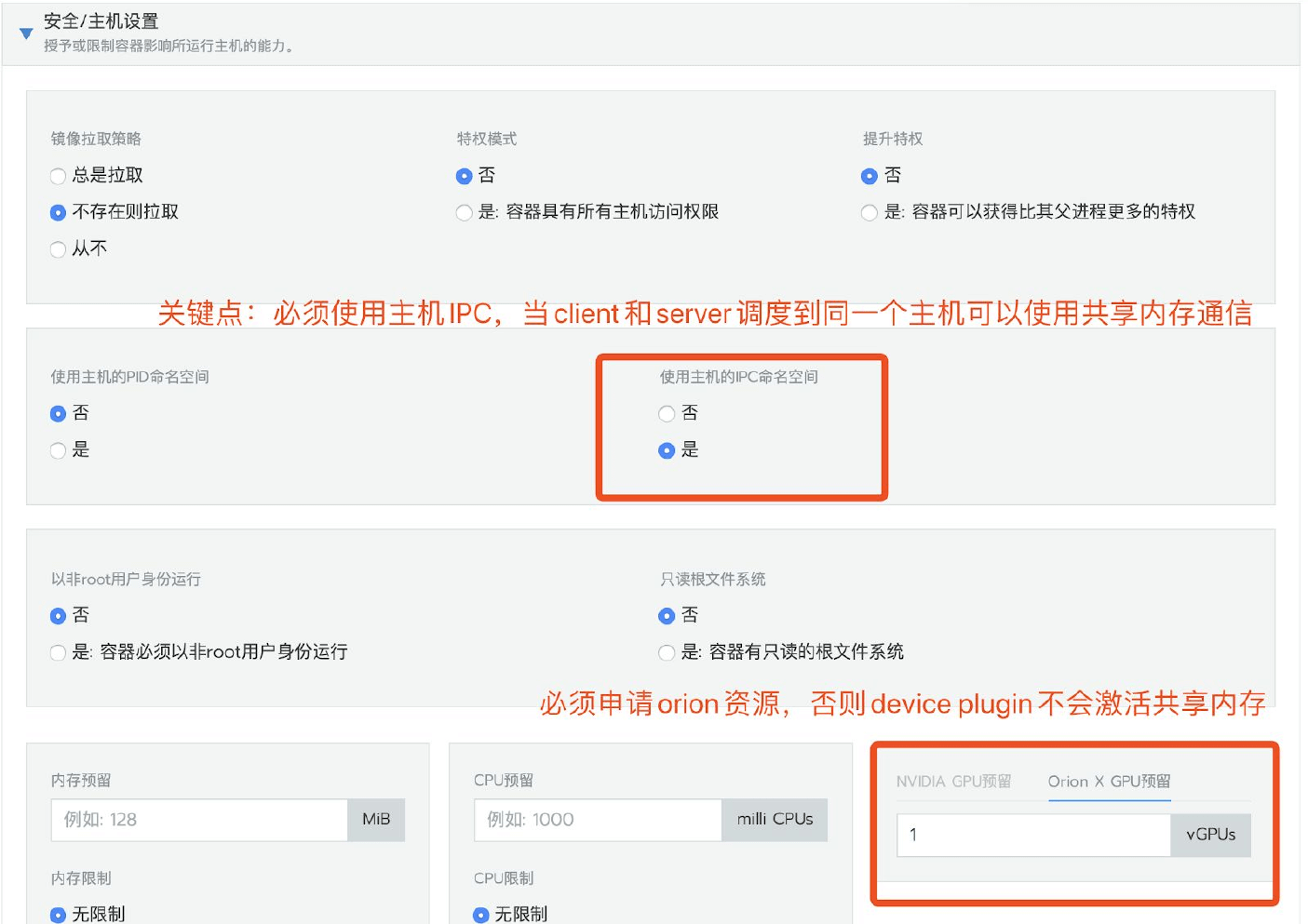
enable_shm = true ; 是否使用共享内存加速通讯
enable_rdma = true ; 是否使用RDMA加速通讯
ibverbs_device = mlx5_0 ; 如果使用RDMA,硬件设备名。仅在boyue Server无法推断硬件时需要配置
[server-nccl]
comm_id = 127.0.0.1:9970; nvidia NCCL通讯的网络和端口
[throttle]
throttle_level = 100 ; 算力控制的隔离程度,取值范围[0, 100]。数字越少隔离越好
enable_computation_throttle = true ; 是否启动算力控制
computation_throttle_mode2 = true ; 算力控制的模式,仅支持true
boyue Server任務控制
通過如下命令可以啟動boyue Server
sudo systemctl start boyued通過如下命令可以執行其他boyue Server操作
sudo systemctl stop boyued ## 停止boyue Server服务
sudo systemctl restart boyued ## 重启boyue Server服务
sudo systemctl status boyued ## 查看boyue Server服务状态
sudo systemctl enable boyued ## 添加boyue Server服务到开机启动服务
sudo journalctl -u boyued ## 查看boyue Server的服务日志
boyue Server的日誌檔
boyue Server的日誌存在兩個位置
- /var/log/boyue/server.log 該檔案記錄了所有boyue Client的握手過程
- /var/log/boyue/session 該目錄以單個檔案的形式,記錄了每次業務運行時的日誌。 每運行一個boyue Client應用,該目錄產生一個獨立的日誌檔。 如果在握手過程中失敗,則不產生日誌檔。
多版本 CUDA SDK 共存
boyue Server可以同時支持多個CUDA版本,使得依賴不同CUDA版本的上層應用可以同時使用boyue vGPU。 為了支持多個CUDA SDK版本,boyue Server要求CUDA安裝在宿主機默認路徑(即/usr/local/cuda-x.y)下麵。 例如為了支持 CUDA 10.0 和 CUDA 9.0,/usr/local 目錄下應該有 cuda-9.0 和 cuda-10.0 這兩個目錄。
此外,多CUDA版本共存時,不需要設定 CUDA_HOME,LD_LIBRARY_PATH 等環境變數,也不依賴於部分用戶環境中存在的軟連結 /usr/local/cuda => /usr/local/cuda-x.y,這是因為boyue Server可以根據boyue Client環境中實際安裝的Runtime對應於CUDA的版本號,動態選擇合適的CUDA SDK版本。
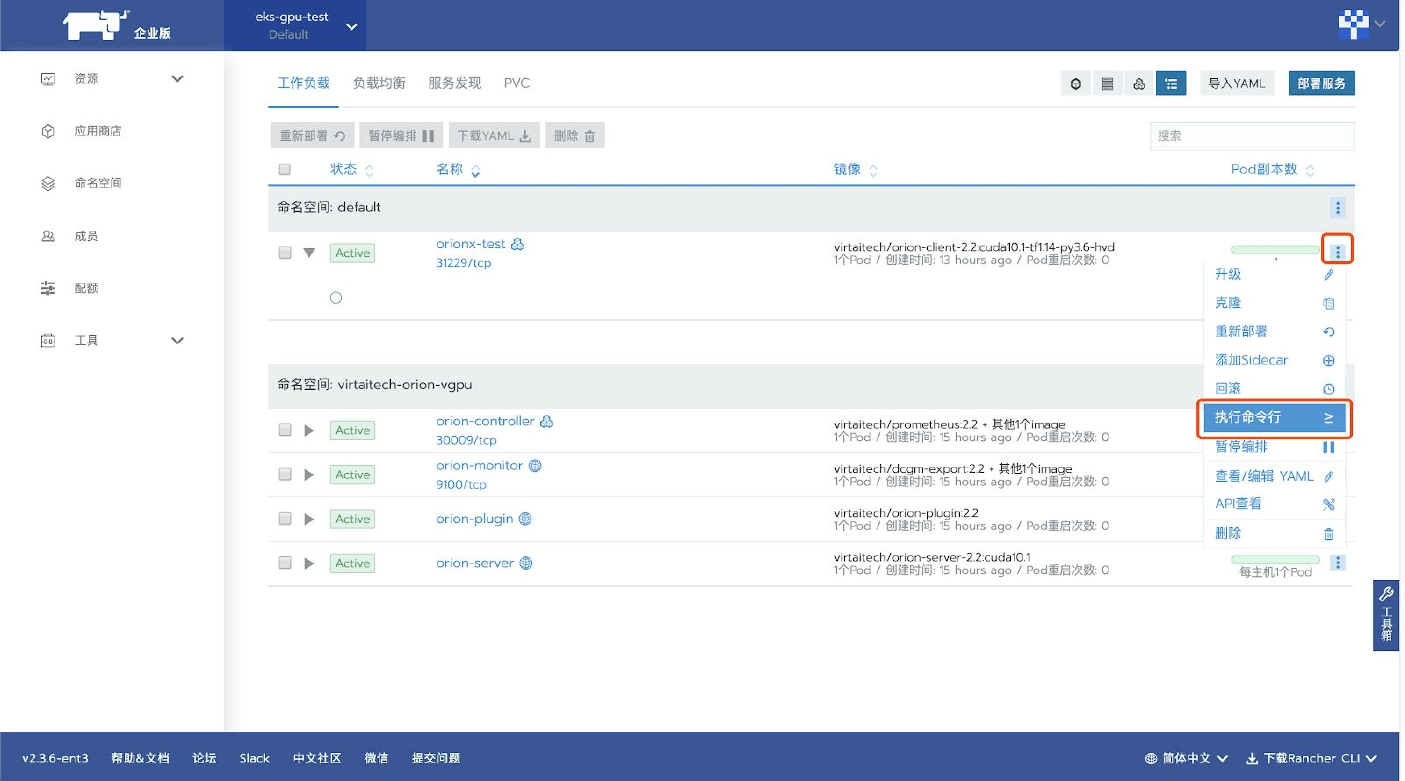
查看 boyue 服務狀態
在同一個局域網內,通過瀏覽器(推薦chrome)訪問boyue Controller所在環境的局域網地址: http://IP:Port
其中IP為boyue Controller所在環境的局域網地址,Port為部署boyue Controller時提示的Web GUI的服務埠。 通過默認用戶名(密碼)登入進入系統:admin(admin)
在側邊欄裏看到boyue Controller的IP地址,點擊展開之後有如下的內容:
- 摘要:顯示boyue Controller所管理的整個boyue vGPU資源池的資源數量,節點狀態等
- 任務:顯示正在運行且使用了boyue vGPU資源的任務,以及每個任務使用的vGPU資源的分布情况
- boyue GPU節點清單:通過點擊展開可以看到一組GPU節點的狀態,並且在每個節點的工作面板上看到物理GPU的劃分使用情况
部署 boyue Client
環境依賴
- g++ 4.8.5 或以上版本,libcurl,openssl,libuuid, libibverbs1
軟體安裝
在CUDA應用環境執行如下的安裝命令
cd /root/boyue/client
sudo ./install-client-x.y
上述命令的x,y為根據所需CUDA版本選擇對應的installer,例如install-client-10.0 對應於 CUDA 10.0
上述命令把boyue Client環境安裝至默認路徑 /usr/lib/boyue 中,並通過 ldconfig 機制將 /usr/lib/boyue 添加到系統動態庫搜索路徑。
注意:如果boyue Client按照到和GPU同樣的宿主機環境,由於boyue Client安裝的/usr/lib/boyue和物理GPU的CUDA SDK可能存在版本衝突。 對於同樣的動態庫在兩個不同磁片位置的加載順序,應該由安裝人員自己維護解决。
配寘 boyue Client
boyue Client 可以通過三類方法配寘運行參數
- 通過環境變數配寘運行參數
- 通過當前用戶home目錄中{$HOME}/.boyue/client.conf設定檔配寘運行參數
- 通過 /etc/boyue/client.conf 設定檔配寘運行參數
上述方法中,通過環境變數配寘的優先順序最高,系統/etc/boyue 目錄中設定檔的優先順序最低
boyue Client 的配寘中分為靜態配寘部分和動態配寘部分。
- 靜態配寘部分指的是在目標環境中每次運行CUDA應用程序都保持不變的部分。
- 動態配寘部分指的是根據CUDA應用程序使用的boyue vGPU資源不同而不同的配寘。
設定檔的格式為:
[log]
log_with_time = true ; 记录日志的时候是否添加时间戳
log_to_screen = true ; 日志是否输出到屏幕的标准输出
log_to_file = true ; 是否记录日志至磁盘文件中
log_level = INFO ; 日志级别,支持 INFO, DEBUG
file_log_level = INFO ; 日志输出到文件中的日志级别
[controller]
controller_addr = 127.0.0.1:9123 ; boyue Controller的调度器IP地址和端口
[client]
enable_net = false ; 是否使用TCP网络和boyue Server通讯
其中環境變數 boyueCONTROLLER 設定 boyue Controller 的地址具有比設定檔更高的優先順序 例如在當前SHELL通過 export boyueCONTROLLER 環境變數可以忽略設定檔中的controller_addr配寘
動態配寘包括:
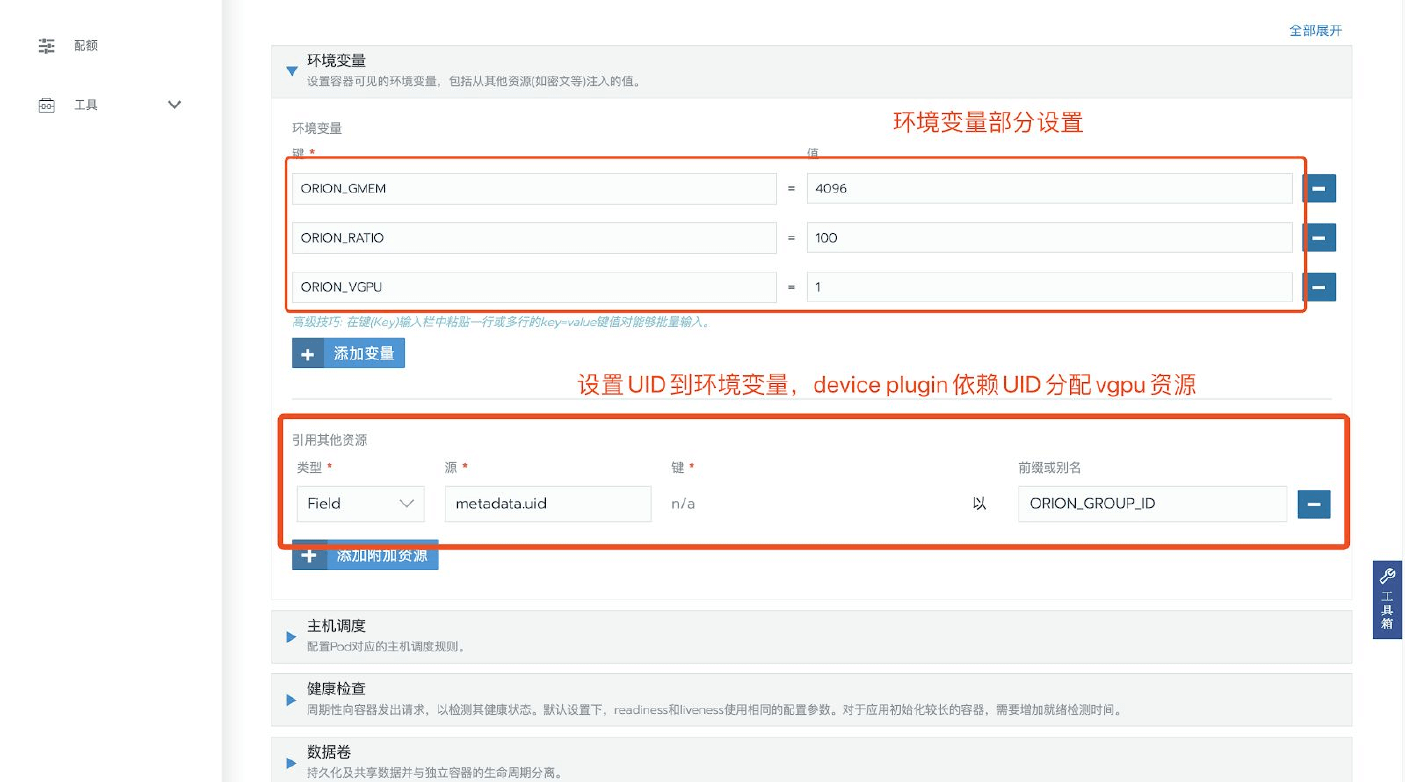
- 環境變數boyue_ VGPU設定當前環境下CUDA應用程序申請使用多少個boyue vGPU
- 例如通過export boyue_ VGPU=2指定了當前CUDA應用程序申請使用2個boyue vGPU
- 該配寘無預設值
- 環境變數boyue_ GMEM設定當前環境下,CUDA應用程序申請使用的每個boyue vGPU中的顯存大小。 以MiB為組織。
- 例如通過export boyue_ GMEM=4096為當前CUDA應用程序指定了每個boyue vGPU的顯存大小為4096 MiB。
- 該配寘的預設值取決於默認一個物理GPU被切分為幾個vGPU
- 環境變數boyue_ RATIO設定當前環境下,CUDA應用程序申請使用的每個boyue vGPU佔用一個物理GPU算力的百分比。 以%為組織
- 例如通過 export boyue_ RATIO=50 為當前CUDA應用程序指定了每個 boyue vGPU 的50%的算力。
- 該配寘的預設值取決於默認一個物理GPU被切分為幾個vGPU
- 環境變數 boyueCROSSNODE 為可選參數,參數為1且申請多個vGPU時,允許boyue Controller跨越多個物理GPU節點調度資源,使得分配的多個vGPU可能來自於不同的物理GPU節點。
- 該參數為1時,boyue_ RATIO必須為100
- 該配寘默認為0
boyue Client日志
boyue Client日誌位於執行應用程序的用戶home目錄中的 ${HOME}/.boyue/log 目錄中。 每次CUDA應用運行均會在該目錄產生一個對應於該次任務的日誌檔。
使用boyue vGPU
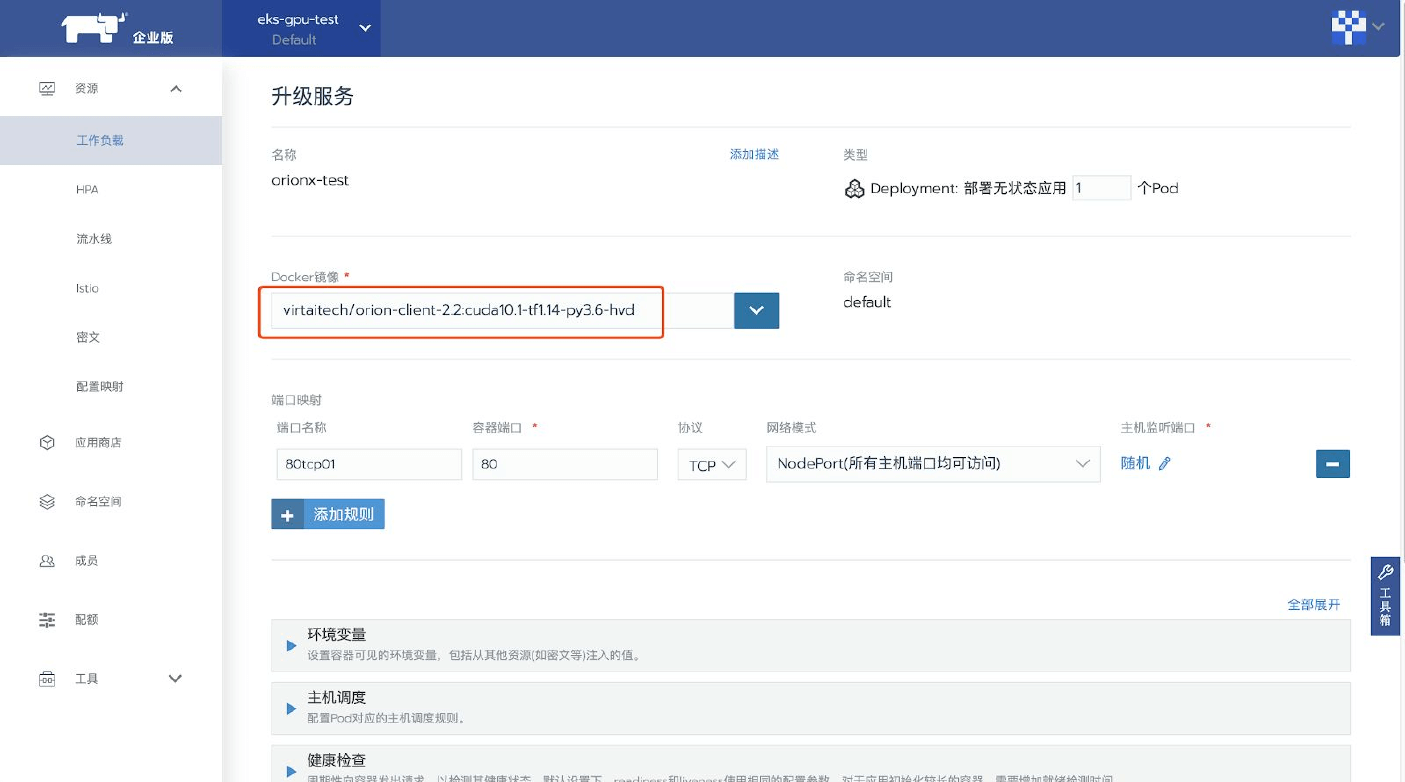
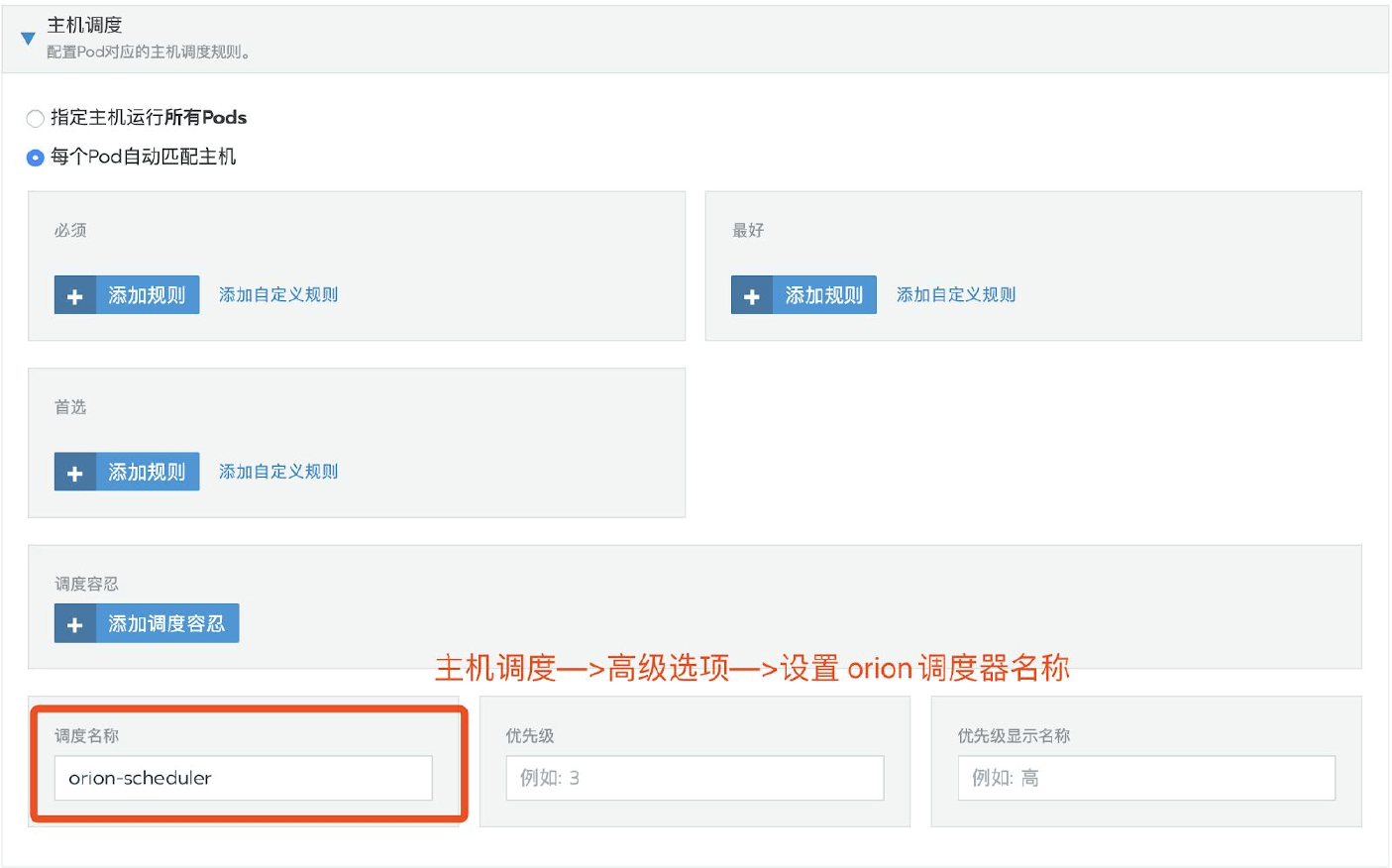
本章節介紹在boyue Client環境中,如何為CUDA應用程序配寘使用boyue vGPU
boyue vGPU資源
通過安裝部署boyue vGPU軟件,所有boyue Server所在的GPU服務器內的GPU均加入了一個全域共亯的資源池。 每個物理GPU均被劃分為多個邏輯vGPU。 劃分vGPU的默認細微性為啟動boyue Server時,設定檔 /etc/boyue/server.conf 中的 vgpu_count 參數指定。 若設定 vgpu_count=n,則每個vGPU默認的顯存大小為物理GPU顯存的n分之一。
boyue vGPU的使用
由於boyue vGPU的調用介面相容物理GPU的調用介面,囙此CUDA應用程序可以無感知無修改地像使用物理GPU那樣使用boyue vGPU。 僅需要在運行CUDA應用程序時,通過設定檔、環境變數為本CUDA應用程序配寘運行環境即可。
經過boyue GPU資源池化之後,資源池中的vGPU使用模式為CUDA應用程序即時申請即時使用的模式。 也即是當CUDA應用程序調用CUDA介面初始化時才向boyue GPU資源池申請一定數量的vGPU,當CUDA應用程序退出時其申請到的vGPU自動釋放至資源池中。 多次調用CUDA應用程序分配到的vGPU不一定對應於同樣的物理GPU資源。
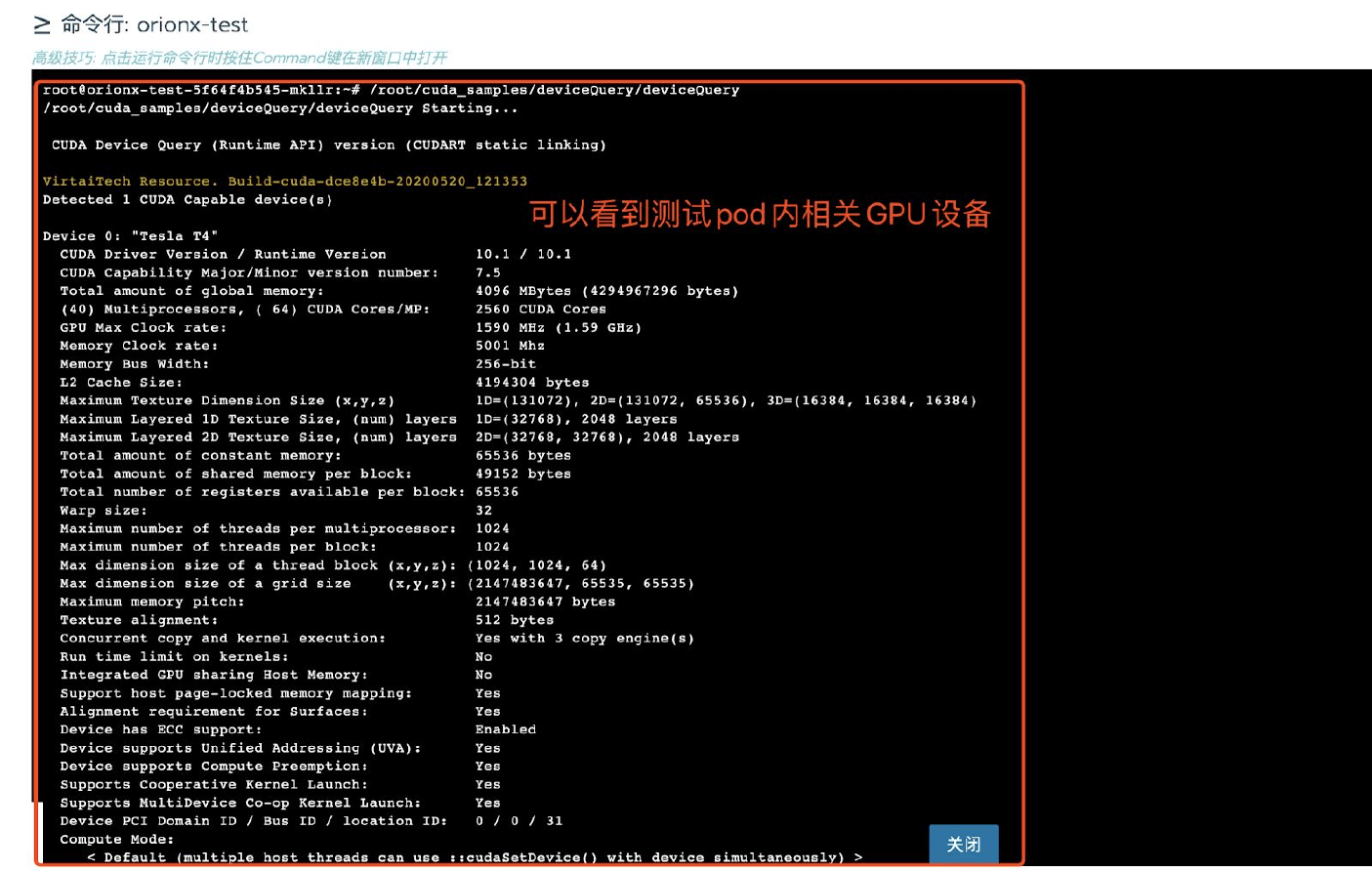
當boyue Client的靜態環境配寘完畢後,在運行一個CUDA應用之前,至少需要用boyue_ VGPU環境變數指明該CUDA應用程序希望獲得的vGPU數目。 例如一個deviceQuery CUDA程式,如下的命令使得當該CUDA程式做設備發現時,通過CUDA的介面査詢到2個GPU,每個GPU的顯存是4096MiB。
export boyue_VGPU=2
export boyue_GMEM=4096
./deviceQuery
當上述deviceQuery CUDA程式啟動時,會從boyue GPU資源池中獨佔兩個vGPU。 該程式結束時,會自動釋放兩個vGPU。 可以通過重新設定環境變數,在運行CUDA應用程序之前改變對vGPU資源的使用。一次CUDA應用程序所申請的多個vGPU可能存在於多個物理GPU上。
vGPU的使用對象為CUDA應用程序,而非物理機、Container或者VM虛擬機器。 即使在同一個環境下運行的多個CUDA應用程序,每一個應用程序都按照當前的運行環境向boyue GPU資源池申請獨立的vGPU資源。 如果並行運行多個CUDA應用程序,則消耗的vGPU數量為應用程序數目乘以boyue_ VGPU所指定的vGPU數目。
常見問題
用戶首先需要確認boyue Server和boyue Client版本的匹配。 不同版本之間的boyue Server和boyue Client無法共同使用。
boyue Client端應用程序啟動報告無法找到NVidia GPU
- 此故障為應用程序沒有使用boyue Client運行庫導致,可能的原因有幾種:
- 該應用程序在編譯期間靜態連結了NVidia的庫,導致其運行時並不調用boyue Client的運行庫。 該問題應該通過設定動態連結並重新編譯解决。
- 該應用程序雖然使用CUDA相關的動態連結程式庫,但是編譯器使用rpath選項指明了CUDA庫加載的絕對路徑,而該路徑並非是boyue Client的安裝路徑。 rpath優先順序高導致庫加載的路徑非期望的boyue Client安裝路徑。 該問題或者通過去掉rpath設定後重新編譯解决,或者用boyue Client運行庫覆蓋rpath指明的路徑內的庫解决。
- boyue Client庫的安裝路徑沒有使用ldconfig或者環境變數LDLIBRARYPATH放到動態庫加載路徑。 該問題通過使用ldconfig永久把boyue Client的安裝路徑加入到系統蒐索路徑,或者正確使用環境變數LDLIBRARYPATH來設定。
- 此故障為應用程序沒有使用boyue Client運行庫導致,可能的原因有幾種:
boyue Server服務無法啟動,boyued行程啟動失敗
- 通過運行boyue-check runtime server來檢查環境。 可能的原因有
- boyued行程依賴CUDA,CUDNN庫無法蒐索到導致可執行文件無法被作業系統啟動。
- 修改上述boyue Server服務設定檔
- boyued行程依賴的其他庫沒有安裝,例如libcurl,libopenssl等