-
業務挑戰:
中國算力規模尤其是智慧算力規模正在高速增長,在政策驅動下人工智慧算力需求穩增,算力發展進入快車道。 今年全國兩會期間,全國人大代表、中國移動浙江公司總經理楊劍宇提交《關於加快推進算力網絡創新發展的建議》中提到:“雖然我國算力網絡發展已經取得較大進展,但是距離讓算力成為像水、電一樣的社會級服務仍有差距。要加快我國算力網絡創新發展,推動算力網絡成為像水、電‘一點接入、即取即用’的社會級服務,夯實數字經濟的數智底座。”
隨著算力總量的大提升,時空維度的分配不均、異構算力管理困難等都是制約算力資源利用率的主要因素。囙此,企業在面對業務對算力不斷高速增長的需求和有限的資源之間的衝突時,關鍵需要統一標準、實現智能化調度,構建起“算力插座”,解决算力接入、調度、智能化匹配等難題。
-
方案簡介:
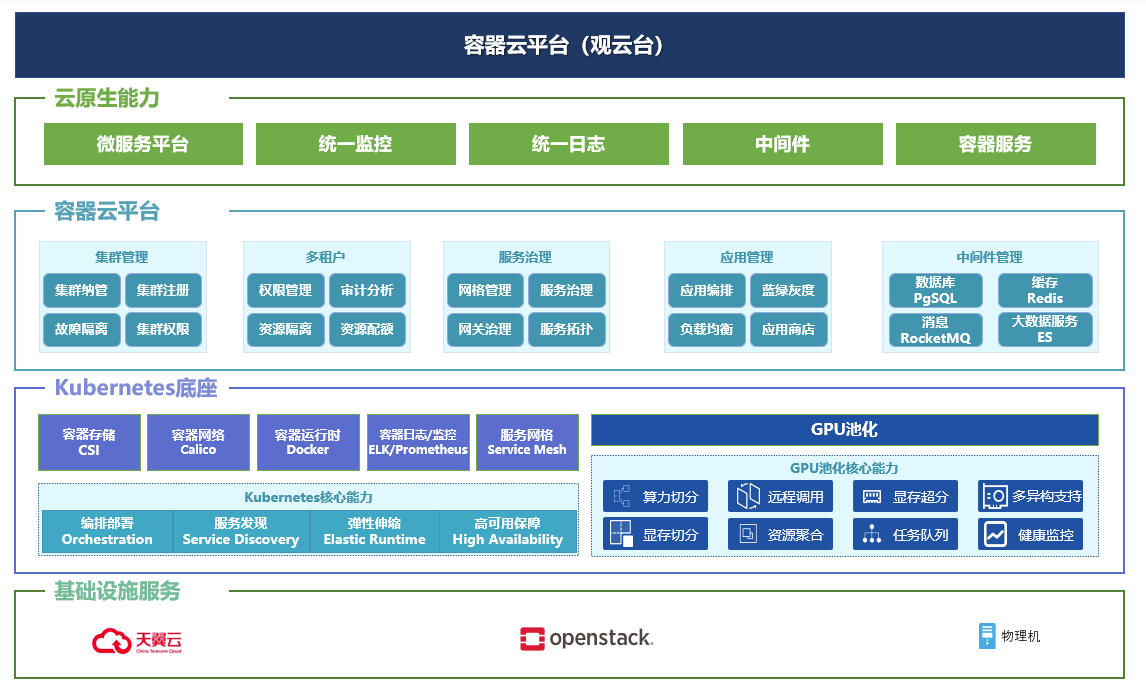
得益於近些年發展得如火如荼的雲原生科技、尤其是作為雲原生科技底座的容器雲科技的高速發展和產業化落地,業界發現,將GPU等算力資源容器化、資源池化,可以使算力的管理能力拓展到整個資料中心。 作為國內為數不多掌握底層核心技術的容器雲產品及解决方案提供商,諧雲以深厚的容器雲底層核心技術,不斷推進Kubernetes相關覈心組件的性能提升和場景適應性,在AI應用支撐、雲邊協同、多雲管理等方面做了大量優化,在AI算力分配上与數字中國GPU池化科技緊密結合,從而實現諧雲容器雲平臺將AI應用和GPU服務器硬體解耦,實現虛擬GPU 資源的動態伸縮和靈活調度,解了對AI、大數據、高性能等計算服務有顯著需求的企業的燃眉之急。
-
方案價值:
-
資源以用戶實際應用需求按百分比分配 AI 加速卡算力,按 MB 分配 AI 加速卡顯存。
-
業務容器可在沒有配寘 AI 加速卡的服務器上運行,並通過 boyue 使用遠端服務器上的 AI 加速卡資源。
-
多個業務容器可共亯同一服務器上的 AI 加速卡資源,同時進行訓練或推理任務,相互隔離。
-
分佈式多卡模型訓練時,可將本地和遠端的 AI 加速卡資源進行自動彙聚以滿足訓練任務對 AI 加速卡資源的需求。
-
支持資源動態分配,當業務容器啟動時,boyue vGPU 資源不會立即分配給該 Pod,在 Pod 運行期間,只有當 AI 應用開始運行的時候,該部分資源才會被該 Pod 佔用,AI 任務結束停止時,資源即被釋放。
-
解決方案架構圖